Understanding advertising effectiveness is crucial for any marketing strategy because it directly impacts resource allocation, campaign optimization, and overall return on investment (ROI). By measuring how well advertisements perform, marketers can determine which messages resonate with their target audience, identify underperforming channels, and refine their creative approach to boost engagement. Effective ad analysis also helps pinpoint the ideal balance between reach, frequency, and targeting precision, ensuring that budgets are not wasted on ads that fail to drive revenue. Moreover, it provides valuable insights into consumer behavior, helping businesses adjust to changing preferences and trends. Ultimately, understanding ad effectiveness enables data-driven decision-making, empowering marketers to create more impactful campaigns that achieve measurable outcomes and foster long-term brand growth.
Integrating experimentation into marketing measurement is one of the most effective ways to achieve advertising effectiveness. You can optimize resource allocation and improve ROI by embedding controlled experiments, such as AB tests or randomized controlled trials (RCTs), into your marketing processes and analytics. In a recent study, those advertisers on an online advertising platform who used ad experiments for measurement saw substantially higher performance than those who did not. An e-commerce advertiser running 15 experiments (versus none) saw about 30% higher ad performance in the same year and 45% in the year after. While this evidence is correlational, it’s reasonable to assume that, in today’s data-driven landscape, experimentation, personalization, and automation are not just a best practice; they are becoming a competitive necessity.
However, integrating an experimentation strategy into marketing measurement can be complex, often requiring large-scale organizational changes and careful planning. This means clearly articulating objectives, establishing a hierarchy for measurement and analytics, selecting the right types of metrics, and determining a system of ground truths and methodologies. You must decide on your marketing and business goals, such as prioritizing ROI or top-line growth. By clearly understanding these goals, you can more effectively design experiments and integrate these with observational analytics to refine your strategies. This ensures that the integration of experimentation is not just a technical procedure but a crucial part of a larger, comprehensive strategy to achieve business success.
In this article, we provide high-level guidance on how you can succeed with integrating experimentation into your marketing measurement.
In the 20th century, the field of marketing experienced a dramatic transformation driven by advancements in data collection, analytics, and communication technologies. Early in the century, marketing effectiveness was primarily assessed through anecdotal evidence and crude measures, such as sales increases and consumer feedback. The rise of mass media—newspapers, radio, and television—ushered in an era of broad audience outreach, leading to the development of audience metrics such as radio ratings and TV viewership statistics. The mid-century saw a growing interest in market research, with the establishment of industry giants like Nielsen providing quantitative insights into consumer behavior.
By the late 20th century, computers had revolutionized data analysis, enabling sophisticated consumer segmentation and predictive modeling. It became common practice to use econometric models to determine the relationship between the various factors in a marketing model. In particular, the field of Observational Causal Inference (OCI) seeks to identify causal relationships from observational data when no experimental variation and randomization are present.
However, as two of the authors recently noted: “Despite its widespread use, a growing body of evidence indicates that OCI techniques often stray from correctly identifying true causal effects [in marketing analytics].[1] This is a critical issue because incorrect inferences can lead to misguided business decisions, resulting in financial losses, inefficient marketing strategies, or misaligned product development efforts.” One of the most common and longstanding OCI techniques in marketing measurement is media and marketing mix models (MMM).
In our recent note, we called on the business and marketing analytics community to embrace experimentation and to use experimental estimates to validate and calibrate OCI models. The community response was vivid, including a contextualizing piece on AdExchanger.
It should be pointed out that this is not a new observation. Many early papers in OCI advocated for experimental validation of modeling results. For example, Figure 1 shows the abstract from a paper by M. L. Vidale and H.B. Wolfe in 1957.

Figure 1. The abstract from “An Operations-Research Study of Sales
Response to Advertising.” (Vidale and Wolfe)
What is new is that, in the modern internet era, wide-scale experimentation is now both possible and widely accessible. It’s still not easy, but it is doable.
In its broadest sense, marketing experimentation refers to any intentionally designed intervention that can help marketers measure the effects of their actions. This includes deliberate variations in spend, share, allocation, or other strategic and tactical decisions made for the purpose of measurement.
For instance, a marketer might introduce intentional variation in daily or weekly spending for a specific channel to estimate its impact on outcomes. By analyzing how performance changes with these fluctuations, marketers can better isolate and quantify the channel’s true effect.
In more extreme cases, experimentation might involve “going dark”—completely halting marketing activity in a specific channel or geographic location. By observing the performance drop (or lack thereof) when marketing is paused, marketers can try to measure the incremental impact of that channel. While this approach can yield insights, it comes with risks (such as confounding variable bias), particularly in high-stakes environments where even short-term losses are undesirable. And it clearly is not an RCT where we know that effect estimates will be unbiased on average.
Narrowing the focus, experimentation can be defined as specifically designed tests that involve treatment and control groups to estimate effects. Under this definition, experimentation encompasses a wide spectrum of tests, ranging from basic ad platform tools to more rigorous methodologies.
Many advertising platforms, like Google and Facebook/Meta, provide split (or A/B) testing tools. These often self-serve tools enable marketers to compare various tactics or creative assets without the need for control groups, using only exposed, non-overlapping audiences. Split testing tools divide the audience into two or more groups, each receiving a different version of the ad. Marketers might also run simultaneous campaigns with varying parameters to observe performance differences.
While these tools can be useful for directional insights, split tests are typically used to optimize specific campaign elements because they fall short of delivering incremental measurements.
Randomized Control Trials (RCTs) are often called the gold standard of effectiveness research. In an RCT, ad exposure is fully randomized across users, with some users serving as a control group who do not see the ad or campaign being measured. This level of rigor ensures that the treatment effect (the ad’s impact) can be isolated and measured without bias on average.
RCTs are widely recognized as the most reliable method for causal inference. However, RCTs are often challenging to execute. Many marketers lack the ability to control ad exposure at the user level, particularly when working across multiple platforms or channels. Privacy regulations and restrictions on user-level data access have further complicated the implementation of RCTs in recent years.
Most ad platforms offer RCTs but sometimes these are not usable without dedicated support personnel (and they often require more effort to implement successfully).
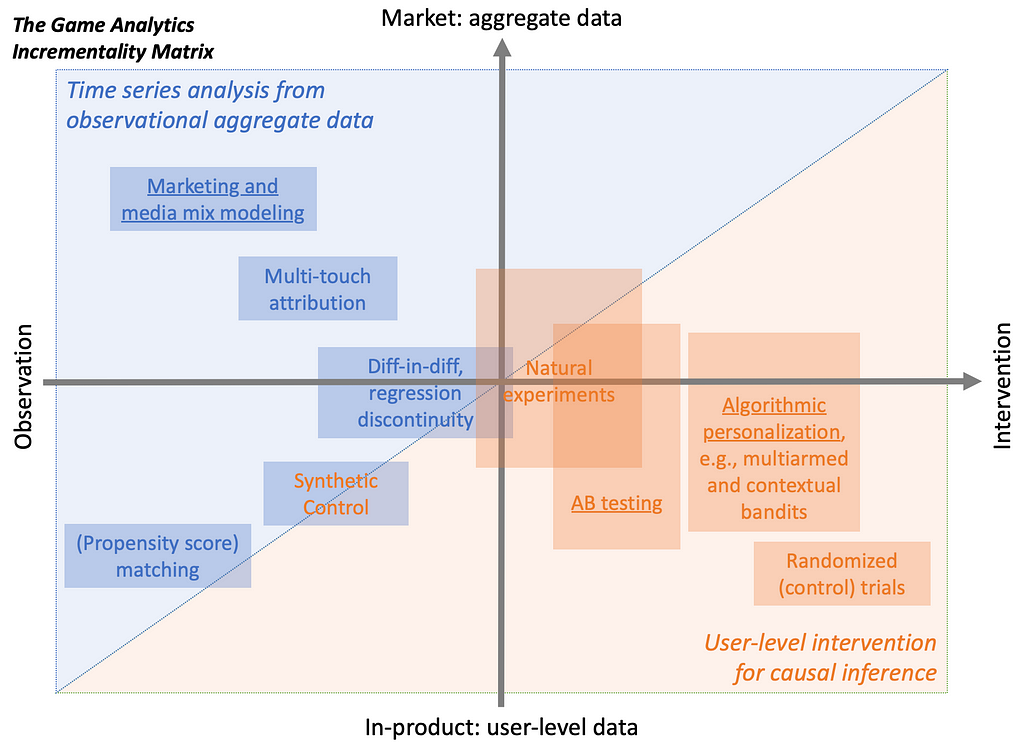
When user-level randomization is not feasible, cluster-level randomization and experiments can offer a practical alternative. In cluster-level randomization, the assignment of experimental ads is managed at broader levels, like geographic regions, rather than at the level of the individual user. With geo experiments, the most common type of cluster experiments, ad exposure is varied at a geographic level – such as ZIP codes, designated market areas (DMAs), or cities – rather than at the level of individual consumers. Some regions serve as test groups, receiving the ad campaign, while others act as controls.
Geo experiments allow marketers to measure the incremental impact of campaigns while avoiding some of the complexities of user-level RCTs. They are particularly valuable when privacy or technological restrictions limit access to granular user data or when there might be spillover effects (a spillover effect is an unintended impact of a marketing intervention or campaign on individuals, groups, or regions that were not directly targeted by the campaign. This can occur when the influence of an advertisement, message, or promotion “spills over” to adjacent groups or regions, leading to indirect exposure and potential behavior changes outside the intended treatment group). Figure 2 below provides an overview of the different types of experiments available to marketers in different situations (source: Figure 1 in this article):
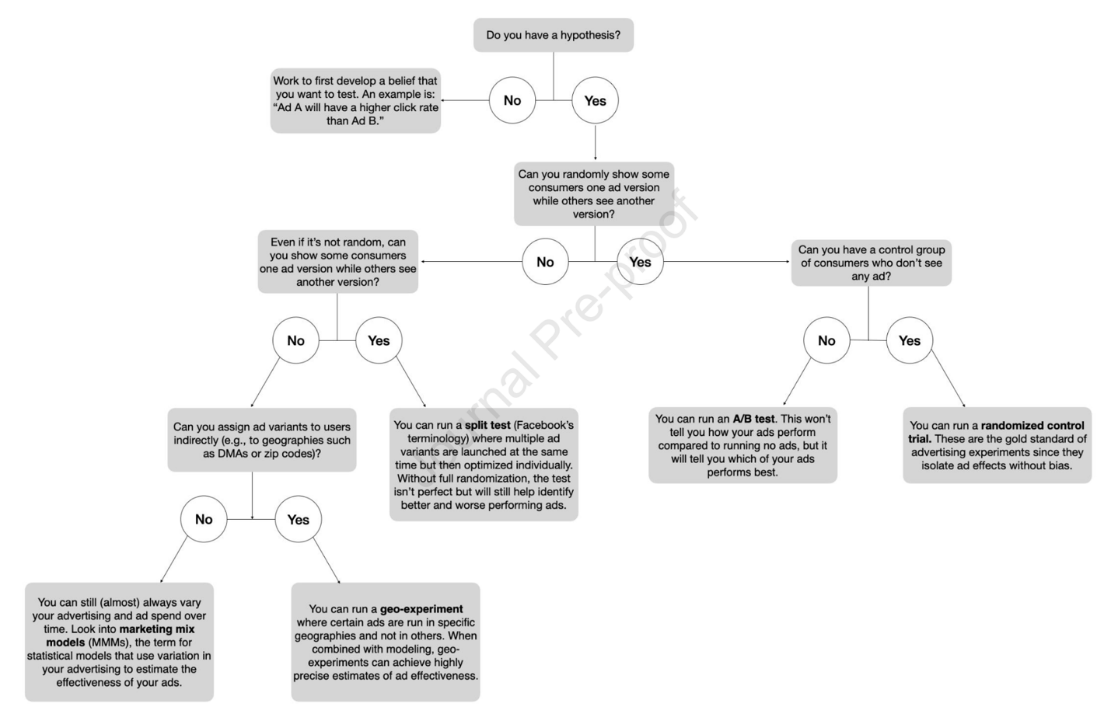
Figure 2. Taken from “It’s time to close the experimentation gap in advertising:
Confronting myths surrounding ad testing.”
There is also another reason that clustered experimentation is sometimes desirable. Choosing a small sub-population, or experimenting within a restricted demographic or geography is often a way to mitigate perceived risk. If key stakeholders are uncomfortable experimenting on the entire population, or worried about the potential impact of spillover effects, isolating to a small sub-population can be a good compromise.
However, clustered experiments are not without challenges. They require careful planning, significant resources, and rigorous execution to ensure clean results. Marketers must account for regional differences, external factors, and spillover effects (where the impact of a campaign in one region influences neighboring regions). It can also be challenging to hold out large cities with attractive contiguous market areas from campaigns, making it challenging to create balanced test and control market groups.
Organizational success with experimentation requires more than just tools and processes. Most of the time, it requires a cultural shift and support. Executives must encourage teams to test hypotheses, embrace failure as a learning opportunity, and prioritize data-driven decision-making. Executive buy-in is critical to ensure experimentation becomes a core part of your marketing strategy. Here are a set of essential steps that can help you succeed:
The foundation of a successful experimentation program lies in having the right people and organizational support. This starts with hiring a dedicated data scientist or analytics team with expertise in marketing measurement and experimental design and analysis. These experts will be responsible for designing, running, and analyzing experiments and ensuring that insights are actionable.
Equally important is securing executive endorsement. A dotted reporting line to a C-level executive can signal the strategic importance of marketing analytics and experimentation. This endorsement helps prioritize the initiative across the organization and ensures that resources are allocated effectively.
For experimentation to thrive, firms must embed it into their organizational culture. This means fostering curiosity, encouraging data-driven decision-making, and rewarding teams for testing assumptions – even when experiments don’t yield the desired outcomes.
Leadership plays a critical role in shaping this culture. By promoting the value of experimentation and celebrating learnings from both successes and failures, executives can inspire teams to embrace testing as a core part of their workflow.
Depending on the setup of your wider analytics organization and if there is a central experimentation team and platform, it can be wise to formally link the marketing analytics group up with the platform team. Research suggests that organizations with mostly decentralized decisions but a single authority that sets consistent implementation thresholds achieve more robust returns to experimentation. Experiment-based innovation and learning further thrive on cross-pollination, which the central team can facilitate.
One of the most challenging obstacles within an organization is overcoming the silos that exist between various departments, such as analytics, planning, strategy, marketing, finance, and leadership. These silos can hinder communication, collaboration, or the flow of information, ultimately impacting the organization’s ability to make data-informed decisions and execute effective strategies.
Bridging these departmental gaps requires a concerted effort to foster a culture of collaboration and open communication. One powerful approach to breaking down barriers is committing to a learning agenda that encourages cross-departmental engagement with shared objectives. By aligning all teams around common goals and promoting continuous learning, commitment to a joint learning agenda can be the single most important step in transforming organizational dynamics.
Ask the marketing analytics team to set clear objectives and a roadmap for experimentation. Every experiment should begin with a specific, measurable goal. The team needs to be able to answer questions like: What do we want to learn? What are the hypotheses we are testing? How will the results influence our decisions? How will we use the results in the wider measurement framework, e.g., to validate and calibrate OCI models? Clear objectives ensure that experiments are focused and actionable. They also help prioritize testing efforts, directing resources toward questions with the highest potential impact.
The true value of experimentation lies in its ability to inform decision-making. Firms need to establish feedback loops where insights from experiments inform future campaigns, strategies, and even the design of new experiments. Regularly reviewing and acting on experimental results, possibly following a fixed-timed process, ensures that insights drive tangible business outcomes. This iterative approach fosters continuous improvement and adaptation to changing market dynamics.
To integrate experimentation into marketing measurement effectively, marketing analytics teams must establish a clear framework that balances rigor and practicality. Here’s how marketers can get started:
Commit to a learning agenda as a practical first step that fosters cross-departmental collaboration and aligns all relevant teams around shared objectives, helping to overcome organizational or communicational silos.
If your team is new to experimentation, begin with simpler interventions, such as introducing controlled variations in spending or campaign parameters. For example, randomly adjusting daily spending across campaigns can help identify baseline performance trends and directional insights.
Modern marketing platforms like Google Ads and Meta Ads Manager include built-in experimentation tools. These platforms allow firms to test different variables – such as targeting criteria or bidding strategies – directly within their campaigns. Use these tools as a stepping stone. While these tests may not meet the highest standards of rigor, they can provide valuable learnings when executed thoughtfully. Ensure you understand the limitations of these tools, particularly around randomization and confounding.
Similarly, if you are primarily active on one or a couple of ad platforms, the provided attribution tools can provide reasonably reliable estimates of your advertising effectiveness. Build on these insights directly to validate and calibrate OCI models if you have those.
Firms can also turn to specialized vendors like Optimizely, Eppo, Adobe Target, or Game Data Pros for more complex needs. These vendors provide advanced capabilities for designing and analyzing experiments and building related software tools. Investing in these tools can streamline the experimentation process and make it easier to scale testing efforts.
Whenever feasible, prioritize RCTs. Collaborate with platforms, publishers, or third-party measurement providers to implement RCTs that deliver unbiased causal estimates. RCTs may not always be practical, but they should remain the gold standard you aspire to. One particular caveat is to make sure there is enough statistical power: insufficient budget or duration can undermine the reliability of the experiment and results. To address this, ensure an adequate budget, duration, and holdout is applied based on power calculations.
As your experimentation capabilities mature, explore geo and other cluster-level randomized experiments to measure the incremental impact of campaigns. Partner with data scientists or measurement specialists to effectively design and execute these tests. Geo experiments can bridge the gap between observational measurement and user-level RCTs.
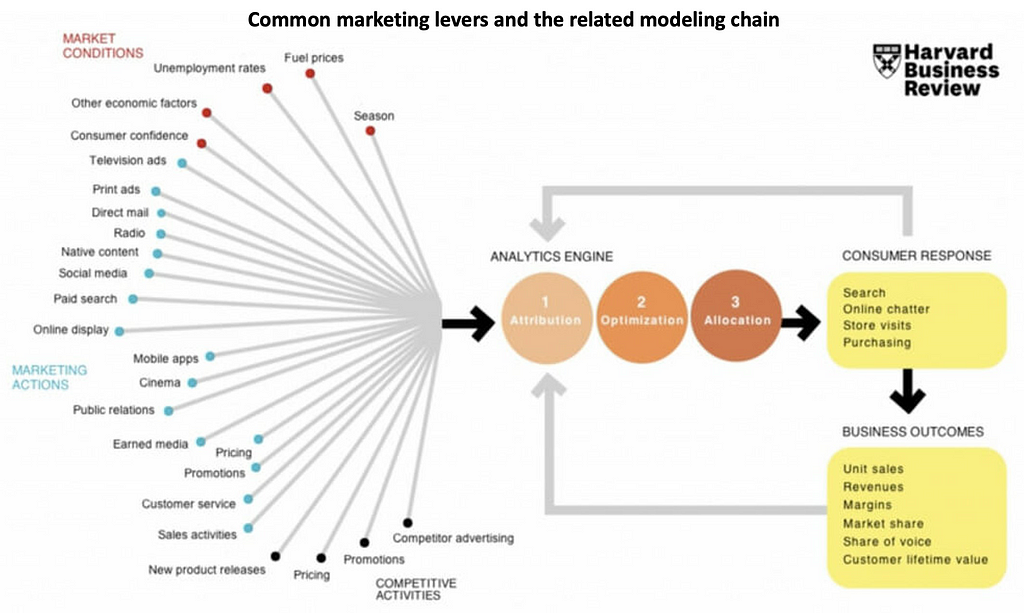
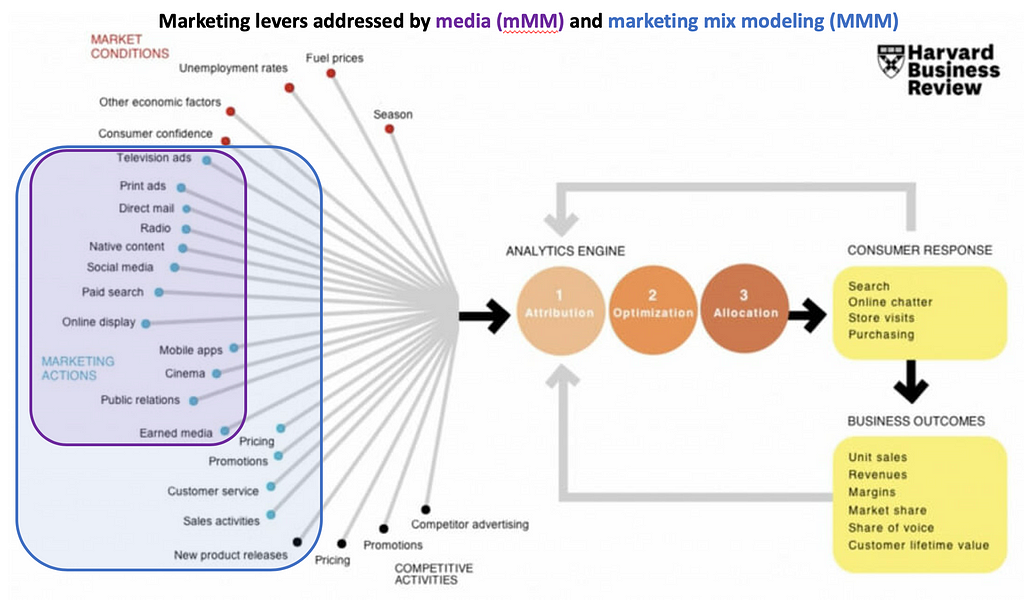
Once your marketing efforts involve more than two channels and you’re looking to scale up, it is time to build a comprehensive measurement framework that captures the full scope of these marketing activities. This involves cataloging marketing activities, i.e., listing all current and upcoming campaigns, channels, and tactics, along with their associated costs and KPIs. The figure in this article may be helpful for this exercise. Then set up a holistic measurement model, e.g., a media or marketing mix model, that includes all these activities plus control variables, trends, and adstock. This article provides an introduction to how you can do this using an open-source package.
A holistic model serves as the baseline for measuring the incremental impact of experiments and provides a framework for interpreting results in the context of broader marketing dynamics. Figure 3, taken from a presentation by Meta, visualizes how different OCI approaches can come together with experimentation.

Figure 3. Taken from a Presentation by Meta.
Take the outputs from split tests, trusted attribution models, geo experiments, and RCTs to validate and calibrate your observational measurement models. To start, you can compare experimental and observational model results to ensure that they are “similar.” Similar can mean that both approaches pick the same winning ad variant/strategy or directionally agree. If the results are inconsistent, update the observational model to achieve similarity.
A somewhat more advanced approach uses experiment results to choose between OCI models. The marketing analytics team can build an ensemble of different models and then pick the one that agrees most closely with the ad experiment results for the KPI of interest, e.g., cost per incremental conversion or sales.
The most advanced and quantitative approach incorporates experiment results into the OCI model directly. Getting this right requires a robust understanding of statistical modeling. In a Bayesian modeling framework, the experimental results can enter your model as a prior. In a Frequentist model, they can serve to define a permissible range on the coefficient estimates: Say your experiment shows a 150% return-on-ad-spend with a 120% lower and 180% upper confidence bound; you can constrain your model’s estimate for that channel to that range.
Under a machine learning approach, you can use multi-objective optimization. Meta’s Robyn package does this: You can set it to not only optimize for statistical fit to observational data but also for minimal deviation from experimental results. This article provides a detailed walk-through of this relatively novel idea.
OCI Models, like all machine learning models, require data for creation and calibration. For example, an advertising channel must have a volume of historical data above a minimal threshold and variations in spend and exposure in order to be meaningfully incorporated into an MMM model.
If an MMM model has an advertising channel with too little data, several strategies can help address the issue. For example, incorporating prior knowledge through Bayesian methods can help stabilize estimates when data is sparse. Grouping similar channels with shared characteristics also allows performance to be estimated collectively, assuming similar behavior. In either case, experiments can quickly generate additional data to validate assumptions.
In conclusion, integrating experimentation into marketing measurement is essential for improving the accuracy and reliability of advertising effectiveness insights. While observational methods like MMM and OCI models provide valuable insights, they can suffer from biases without experimental validation. Controlled experiments can help calibrate and enhance these models by offering unbiased causal estimates.
However, success with experimentation requires work and planning. It requires an organizational commitment to data-driven decision-making, cross-departmental collaboration, and continuous learning. By aligning hypotheses, leveraging platform tools, fostering a culture of testing, and iteratively improving OCI models with experimental data, organizations can optimize resource allocation, better measure performance, and seize new growth opportunities across channels. Ultimately, experimentation transforms marketing from intuition-based strategies to a rigorously tested framework that drives both short-term results and long-term growth.
The effort is worth it though. Evidence is mounting that OCI can often stray far from the estimates of RCTs and that firms that embrace experimentation as an analytics strategy do better. It’s not either OCI or ad experiments. It’s OCI and ad experiments.
We hope our article will help you get started.
[1] For the case of advertising, e.g., see Blake, Nosko & Tadelis (2015), Gordon et al. (2019), or Gordon, Moakler & Zettelmayer (2022); for the case of pricing, Bray, Sanders & Stamatopoulos (2024).