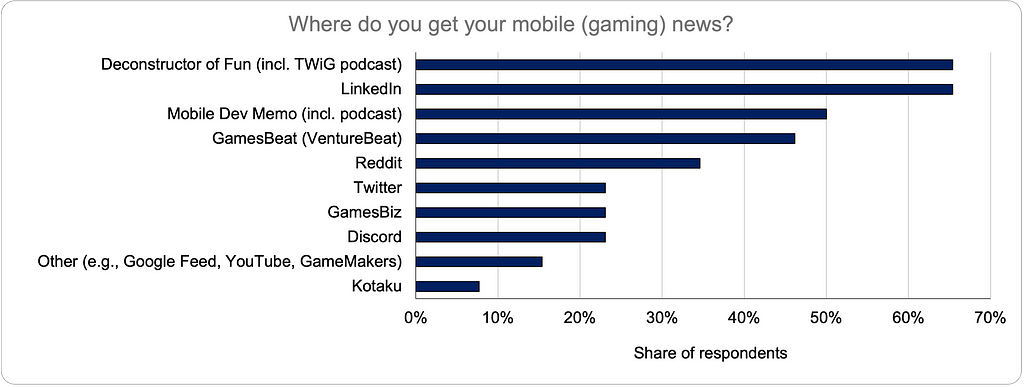
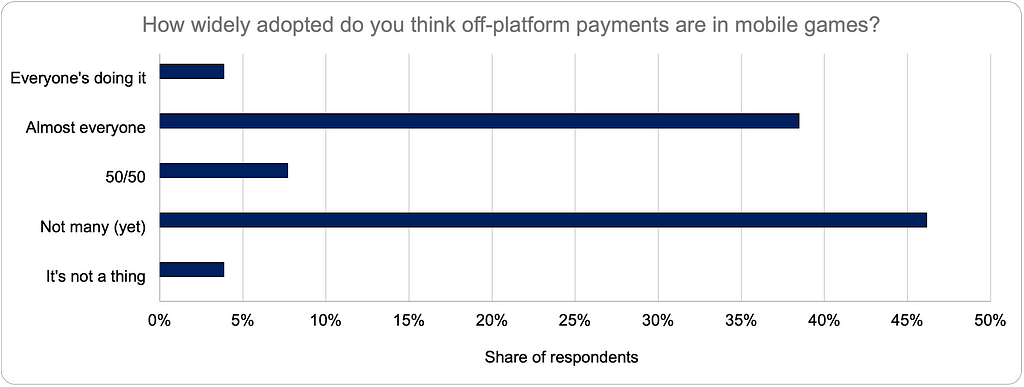
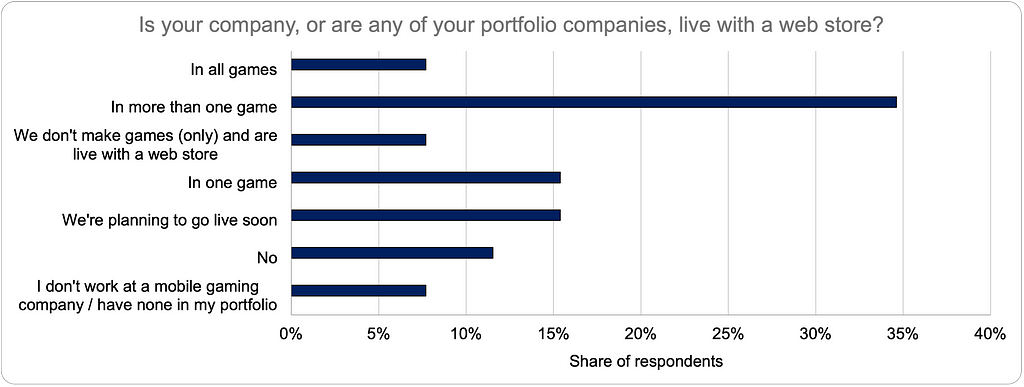
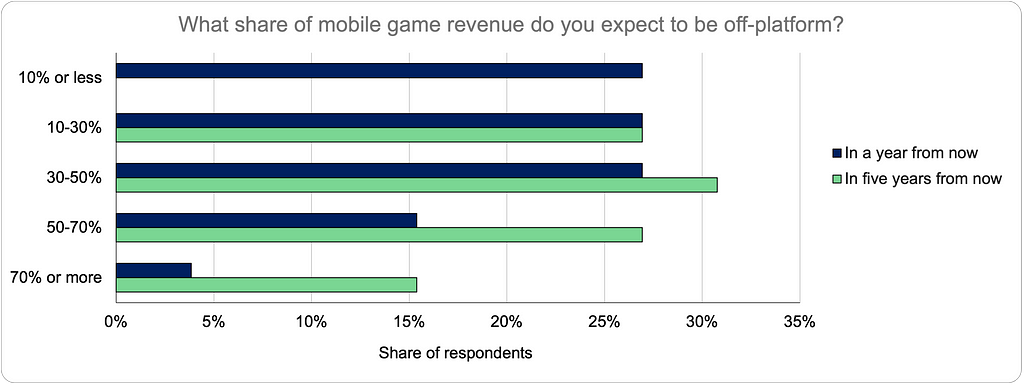
At various points in the past year (at the 2025 Game Revenue Optimization Mini-Summit and, more recently, on LinkedIn), I’ve been an advocate for a take that makes some people uncomfortable:
Open Source is Going to Dominate the Future of Commercial MMM.
When I say that in private conversations, I usually get one of two flavors of pushback.
- “Sounds like a big change. What do you mean by dominate?”
- “You do game revenue optimization for a living — talking about the future of MMM isn’t exactly in your swim lane. Why do you care?”
The second question is easy. In mobile games, marketing measurement isn’t an analytics side quest — it’s part of the core loop. If you can’t measure incrementality, you can’t compute marginal Return on Advertising Spend (ROAS) or forecast payback. If you can’t compute marginal ROAS or forecast payback, you can’t scale. And since GDP occasionally gets retained to help evaluate user attribution and marketing measurement systems and build roadmaps, our customer base is effectively saying: “Yes, GDP, this is precisely your swim lane.”
The first question is harder, because “open source will dominate” is imprecise and implies a significant change in the market. Let’s start by defining dominate.
By dominate, I mean the default foundation for serious MMM implementations will be open-source frameworks like Meridian or PyMC and that most commercial value will move up-the-stack into integration, operations, governance, and domain-specific modeling.
How will this happen? The rest of this article contains a set of predictions for how the commercial landscape of MMM technology will evolve over the next 3–7 years (and why I think that the excellent provider maps from Marketing Science Today are going to change dramatically as a result).
This article is formulated as a set of nine specific predictions that, collectively, justify the claim that open source is going to dominate the future of MMM.
Before we get started, it’s important to note that, conceptually, an “MMM implementation” divides into four pieces:
- The core computational engine and algorithms (aka “engine and modeling capabilities”). This is the hard data science code and is also commonly referred to using the following names: model layer, inference engine, and model training engine.
- A set of applications that use the trained model provided by the MMM to make recommendations (e.g., spend optimization and revenue forecasting).
- A structural model and set of data definitions. This is the data-modeling part of the job and is also commonly referred to by the following names: model structural form, measurement framework, data and metrics taxonomy, schema & definitions, or semantic model.
- A set of integrations into data sources and production processes to run the engine / algorithms.
The first claim I’m making is that open source will take over the first two bullet points. And the second claim I’m making is that, depending on company size, companies will either do the work associated to the last two bullet points themselves, or use an industry/vertical specific provider that leverages the open-source frameworks from the first two bullets (Larger companies will roll their own; smaller companies will use a vendor).
And, of course, if you’re the sort of person who likes their predictions laced with some empirical validation, everything I’m talking about in this article is already happening (per William Gibson, the future is already here. It’s just not evenly distributed).
Here, for example, is a recent post from LinkedIn:

Source: https://www.linkedin.com/feed/update/urn:li:activity:7407778595366125568/
With that said, let’s get started.
Prediction #1: No Private Vendor Will Maintain a Durable “Engine and Modeling Capabilities” Edge Over Open Source Frameworks
If you’ve worked in software long enough, you know how this goes.
A core technology becomes strategically important and broadly applicable. Open-source communities form. Enterprises start contributing. Vendors stop competing on the core algorithms and software capabilities, and start competing on packaging, workflow, and services.
And here are three examples from recent history:
- Kubernetes became the de facto substrate for container orchestration; CNCF research puts Kubernetes in production at roughly 80% of orgs, and the ecosystem that grew around it is enormous.
- IBM paid $34B for Red Hat, a company that built an enormous business packaging, supporting, and hardening an open-source operating system written by other people.
- PostgreSQL is now the most popular database in Stack Overflow’s survey, despite decades of proprietary database incumbents. The second and third most popular choices are also open-source. And Amazon makes a substantial amount of money providing managed hosting services for these databases.
MMM is lined up for the same pattern because it has the same properties as databases, operating systems, and orchestration frameworks. That is, it has:
- High strategic value. Being able to optimize advertising spend is mission-critical for most companies.
- Low “technical secret sauce.” MMM has sixty years of academic research behind it and the core ideas are well-understood. The core ideas have been refined, and re-refined, and most MMM engines have easily understood structural models.
- MMM is not core competence. For most companies, MMM is an analytical tool that helps them allocate advertising spend more effectively. From a business perspective, the real differentiation is elsewhere (product, brand, …).
- A constant need to evolve in response to platforms changes. In fact, the modern resurgence of MMM, at least in some verticals, dates back to Apple’s decision to change privacy rules (for the current rules on iOS, see Apple’s ATT docs and Apple’s SKAdnetwork docs)
- A shared problem structure across companies. This will be revisited more extensively below in Prediction #6. For now, suffice it to say that two educational software companies that ship mobile apps and charge a subscription are very likely to have similar MMMs implementations, and there is little or no point to them investing in building the underlying technology.
- A huge premium on transparency and trust. In many ways, this is part of “high strategic value.” If a tool is being used to make important decisions, it needs to have a high level of transparency and trust. And MMM is especially vulnerable to open-source standardization because the trust surface area is huge: inputs, priors, assumptions, diagnostics, and decomposition logic all need to be inspectable.
The first three of these argue that companies will outsource development of MMM technology. The last two imply that if your commercial moat is “our engine and algorithms are better but we can’t tell you why because trade-secret,” you might run into problems as the market matures.
Prediction #2: Most Major Companies Will Run Internal MMM Systems On Top of an Open-Source Codebase
The first part of this prediction centers around the following question here: at scale (say, $100M in annual media spend), should a company rely on an MMM run by an MMM vendor? The answer is that, for many brands, this doesn’t make sense. Instead, most large-scale advertisers should and will run and maintain MMM systems internally, even as they lean on external experts for initial setup and periodic checkups.
Why? Because at a certain scale, the MMM isn’t a model or an algorithm or a separate piece of software. It’s part of a much larger system comprised of
- Data contracts with a large number of other marketing systems.
- Features engineered on top of proprietary data (which, in many cases, cannot be shared or has to be scrubbed extensively before sharing for compliance reasons).
- Integrated experimentation layers.
- Stakeholder workflows, customized dashboards, and integrations to internal planning and financial systems.
- Repeatable forecasting routines.
All of this is incorporated into an internal suite of truth, and is tied to mission-critical, highly visible, processes that are often company specific (that is, the decision to bring the MMM in-house mostly means owning the data contracts, the refresh cadence, governance, experiment and integration, …. not re-inventing Bayesian inference).
And once a company decides to use an internal system, the decision to leverage robust open-source framework is an easy one to make.
This trend is already visible. Google’s Meridian is explicitly positioned as enabling advertisers to run in-house MMM. And Meta’s Robyn was built for “in-house and DIY modelers,” with published case studies including in-house applications.

(Taken from https://facebookexperimental.github.io/Robyn/docs/analysts-guide-to-MMM/)
The interesting second-order effect is contribution. Once enough big companies run open-source MMMs in production, they’ll start contributing code and fixes back. Not out of charity, but because maintaining private forks is expensive and they want the ecosystem to solve shared problems in standard ways (like clean room inputs, reach/frequency handling, calibration tooling, and standardized diagnostics).
That flywheel is why open source solutions tend to accelerate once they reach critical mass (and it’s also why private solutions, once they fall behind, never catch up). And accelerating flywheels lead to dominant solutions.
Prediction #3: The Two “Leading Open-Source Bayesian MMMs” Will Become Fundamentally Different Systems Over Time
Right now, the two Bayesian open-source platforms that are leading the conversation are Google’s Meridian and PyMC-Marketing’s MMM.
They’re both Bayesian. They’re both open source. But they don’t feel like the same product at all.
- Meridian is an opinionated framework that gets users to useful answers quickly. It comes with a coherent worldview about modern measurement: the importance of geographic structure, calibration via priors, and support for reach/frequency modeling.
- PyMC-Marketing, even though it has two highly-usable MMM classes, is more of a flexible toolkit. It’s deeply composable, and it’s built on top of the broader PyMC ecosystem. It also leans into model evaluation and cross-validation patterns that expert modeling teams care about (see, for example, the excellent notebook discussing time-slice cross-validation).
(If you want a deeper comparison, there are already multiple comparisons floating around, including a head-to-head benchmark from PyMC Labs and some excellent practitioner writeups. See, for example, this comparison from early 2025 or this pair of articles from PyMC)
My take is simple:
- If you’re resource constrained and need a tighter “path to value,” Meridian’s ease of use is a very nice feature. Both Google and the community will lean into that, making MMM easily accessible to a large number of lightly-resourced companies.
- If you have strong internal modeling expertise and you need to build something bespoke (hierarchical, multi-outcome, time-varying, experiment-informed coefficients, …), PyMC-Marketing is the more extensible base. And PyMC will lean into that, in the process becoming the enterprise toolkit for MMM.
- This gap will widen over time because Meridian will optimize for adoption and repeatability, while PyMC will optimize for extensibility and enterprise-grade composability.
Of course, these first three predictions are the backbone of the prediction everyone wants to argue about.
Prediction #4: By 2030, Many Enterprises Will Run “Open-Source MMM / In-House Team / Ecosystem Contributions”
Today, most enterprise MMM “systems” are still a patchwork of legacy martech tools, bespoke SQL, and spreadsheet glue—refreshed quarterly or semi-annually and dependent on a few heroic analysts. That’s why this shift will feel less like “switching models” and more like infrastructure modernization: once the core technology is standardized, the real work becomes building durable data contracts, QA, governance, and decision workflows around it.
The general pattern is the same one we’ve seen elsewhere:
- MMM is becoming infrastructure.
- Infrastructure gets standardized.
- Standardization favors open source.
- Enterprises keep control of the instance, the data, and the business logic.
The best mental model here is Kubernetes. Kubernetes won not because one vendor stayed ahead forever, but because it became the standard substrate that everyone extended: cloud providers, security tooling, observability, deployment pipelines, and internal platform teams. MMM is headed toward the same kind of ecosystem. Once a handful of large advertisers operationalize open-source MMM, you’ll see an explosion of “everything around the model”: data connectors, calibration pipelines, scenario tooling, automated QA, governance, and decision workflows.
And this is where contributions become inevitable. In practice, “contributing back” won’t look like brands publishing their spend curves or revealing confidential information. It will look like bug fixes, stability improvements, new diagnostics, better infrastructure for priors, standardized data schemas, and reference implementations for common patterns (geo hierarchies, reach/frequency, promotions, creative fatigue). Those are the shared problems that everyone wants solved once and then maintained by the community.
So, the MMM vendor category doesn’t disappear. Instead, it moves up-the-stack, from “owning the engine” to “owning deployment, governance, integrations, and vertical packaging.”
Prediction #5: Most Providers in the “MMM Platform Map” Will Be Forced to Pivot (Or Become Commoditized)
If you look at provider maps like the one above from Marketing Science Today, you’re basically looking at a snapshot of a market where most of the enterprise value is currently held by:
- Proprietary implementations.
- Bespoke onboarding and integrations.
- Customer lock-in.
- Opaque modeling decisions that are hard to replicate.
Once the open-source substrate becomes standard, a substantial percentage of that value simply evaporates.
Some vendors will still win—not by owning the engines and algorithms, but by owning integrations into clean rooms and walled gardens, governance/model risk tooling, change management, and the operational layer that makes MMM usable week-to-week.
MMM consultants will continue to prosper by offering specialized services (in much the same way that Percona helps companies get the most out of their open-source databases). Enterprises will have internal MMM teams that know the business deeply. They’ll still need help with the initial development of their MMM, and specialist help when things go south in a complicated way.
And some companies will offer “MMM as a service” on top of the open-source platforms. I expect that the way this will roll out is that a company will develop deep expertise in a specific vertical (see the next prediction), and operate and maintain the MMM in production for smaller companies (that don’t want to have expertise in keeping an MMM running). Note that these will be relatively thin layers on top of open-source frameworks.
What won’t prosper is proprietary engines or algorithmic / data-science code.
Prediction #6: Verticalized MMM Becomes a Real Category (And It Will Look Like “Open-Source / Hosting / Domain Expertise”)
Here’s the (slightly) exaggerated version of an important claim:
Companies in the same vertical need the same MMM (in everything except the data. And mostly the same data too)
This is not a new insight. In 2005, in an article entitled Market Response Models and Marketing Practice Hanssens, Leeflang and Wittink talked about “standardized models” and “the availability of empirical generalizations.” And in 2009, in an article entitled Market Response and Marketing Mix Models:
Trends and Research Opportunities, Bowman and Gatignon explicitly talked about “Industry Specific Contexts.” Newer work and meta-analyses show that response patterns can be meaningfully different in specific sectors (e.g., entertainment), limiting naïve transferability and strengthening the case for vertical-specific defaults, priors, and diagnostics.
To make this more concrete, consider the following verticals:
- Subscription digital goods (streaming, SaaS-ish consumer apps, memberships). Focus: long payback windows and retention-driven growth. Core issues: linking media to CAC/LTV, cohort behavior, and delayed revenue realization (making outcome measurement unreliable).
- Mobile video games / live-service games. Focus: both acquisition and re-engagement, with marketing organized around strong content beats. Core issues: mixed performance + brand dynamics, event-driven baselines, platform signal loss, overlapping measurement systems, creative fatigue, and the need for high-frequency (daily/weekly) budget adjustments.
- DTC e-commerce for physical goods. Focus: heavy paid social/search, promotion calendars, and operating within inventory constraints. Core issues: major confounders from merchandising/pricing/promo strategy, and separating media effects from cultural events and seasonality (e.g., holidays).
- Omnichannel retail (brands with physical stores and online commerce). Focus: coordinating a wide mix of legacy and digital media across multiple purchase paths. Core issues: inconsistent measurement units (e.g., GRPs vs. impressions), geo/store hierarchies, distribution changes, attributing media to footfall vs. online activity, and disentangling holiday-driven demand from true incrementality.
- QSR / food delivery (fast food, restaurants with delivery, delivery aggregators). Focus: local demand generation with always-on promotion strategies, increasingly tied to digital outcomes (e.g., app installs, online orders). Core issues: localized dynamics, promo-driven demand shifts, weather sensitivity, competitive pressure, and multi-outcome measurement across in-store and digital channels.
- Healthcare services / providers (health systems, urgent care, dental/ortho, telehealth). Focus: high-consideration decisions with conversions that often occur offline (calls, intake, scheduling) and vary heavily by geography. Core issues: multiple outcomes (inquiries, appointments, treatments, and revenue), long and variable lags in ad response, capacity constraints (clinician supply and scheduling), compliance concerns, and confounders like payer mix/open enrollment cycles, network changes, local competition, and seasonal demand shocks.
- … (feel free to add Education, Insurance, … )
Each of these verticals is clearly distinct from the others (the requirements for digital subscription goods are very different from those for healthcare), and each is ripe for a standardized model and SaaS services built on top of hosted open source.
That is, companies in a single vertical aren’t identical, but they are similar enough that you can build a single verticalized MMM system. Such a system would have:
- A canonical data model / structural form.
- A set of priors and response curve defaults.
- A standard set of confounders.
- A standard set of integrations to vertical-specific tools.
- And a standard reporting workflow.
Note also that building this, in the open-source world, requires deep domain expertise, and just-enough MMM expertise to encode the right confounders and workflows (but not the kind of research-grade modeling and coding effort required to build the core framework). In other words, this is best done as a layer on top of the open-source MMM toolkits that are already available.
I also expect that many of these companies will actually be “spun-out” from companies already doing business in the vertical (in the same way that Discord began life as the communication layer of Fates Forever).
The prediction is that the open-source community will build and maintain the hard data-science parts, as both out of the box systems and as extensible toolkits, and the vertical-specific hosting companies will build and maintain the domain specific models (and compete on domain expertise, not MMM expertise)
Prediction #7: After Vigorous Debate, the Industry Will Converge on What “Accurate MMM” Means (And It Won’t Be a Single Number)
Right now, the idea of “accuracy” is a mess. Two different groups of people, or two different MMM providers, can both say “our MMM is highly accurate” and mean completely different things. For example, they could mean:
- The model has high R² (or RMSE. Or NRMSE, NMAE, …)
- The model has good out-of-sample prediction error (e.g., using one of RMSE / MAPE / wMAPE / sMAPE / MASE, NRMSE, NMAE, …)
- The model backtests well.
- The model matches lift test and incrementality tests.
- When we run the MCMC sampler again, we get the same results (note that we’re not including sampler metrics, like BFMI, in this list because they matter for reliability, whether we can trust the outcome of the sampler, but aren’t about accuracy).
- The results are stable under time-series cross-validation.
- The decomposition looks plausible to domain experts.
In order to progress, the industry has to move toward a layered standard that looks like:
- Predictive sanity checks (R², RMSE, MAPE, wMAPE, etc.) with vertical-specific values for “good” and “great” performance (e.g., a 10% wMAPE is probably excellent in omnichannel retail, but not nearly as impressive in subscription digital goods).
- Stability checks (time-slice CV, holdouts, parameter stability)
- Decomposition plausibility (no insane baselines, response curves make sense to industry experts, and so on)
- Calibration / validation against experiments (geo lift, conversion lift, interrupted time-series analysis)
Note that everyone is starting to talk about accuracy and performance measurements more seriously. Meridian’s documentation explicitly states the goal is causal inference, and that out-of-sample prediction metrics are useful guardrails but shouldn’t be the primary way fit is assessed. Similarly, PyMC-Marketing explicitly documents evaluation workflows and time-slice CV, including Bayesian scoring like CRPS and Recast has been a staunch advocate for stability and robustness.
The consensus will be less like “everyone uses metric X” and more like “everyone uses a shared evaluation playbook which is customized by vertical.”
Prediction #8: “Interoperability in the Marketing Stack” Will Stop Meaning “Everything has a Dashboard”
Today, most marketing systems are tied together at the dashboard level. System A produces a chart. System B produces another chart. A smart human stares at both charts and then decides what to do.
That’s not interoperability in any real sense. That’s parallel usage (possibly accompanied by “storing the data in the same relational database”)
In the next iteration of marketing measurement, interoperability will mean:
- Shared metric definitions.
- Shared data sets.
- Machine-readable outputs.
- And automated decision workflows (with humans supervising, not translating).
AI is going to accelerate this, not because LLMs magically fix data, but because they dramatically reduce integration friction.
Protocols like MCP (Model Context Protocol) are basically “standard tool interfaces for AI systems,” and they’re already being applied to analytics. AI tools enable companies to deal with messy and unstructured data and dramatically lower the barriers to system integrations. Ad Exchanger recently published a nice summary of the value of MCP but the key point is simply this: the adoption of MCP is spreading rapidly (for example, Google ships a Google Analytics MCP server so an LLM can connect to GA4 data directly, you can manage your Facebook ads via MCP, analytics vendors like Mixpanel have adopted MCP, and so on). Once MMM outputs and measurement systems are exposed through standard interfaces, LLM-driven agents can:
- Map schemas across platforms
- Translate metric definitions
- Generate and maintain transformation code
- And reconcile “same concept / different naming” problems that currently require senior analysts and significant amounts of tribal folklore.
This is the tedious plumbing work that marketing stacks have always needed… and never staffed adequately. And now it’s, if not easy, doable.
Prediction #9: Standardization Creates Shareable Datasets, Enabling Academic Research that Will Accelerate Model Progress
In the long run, standardization creates three things (that don’t exist today at scale):
- Benchmark datasets (mostly synthetic and semi-synthetic) with known ground truth as well as standard definitions for metrics and data elements.
- A shared evaluation suite (the “accuracy playbook” from Prediction #7, but runnable as code).
- Privacy-safe collaboration patterns that let companies share researchable artifacts without sharing raw sensitive data.
Once those exist, academics can stop doing “MMM research in the void” and start iterating against problems that look like production.
There are already efforts aimed at connecting academics, advertisers, and vendors around MMM research (e.g., industry initiatives convening multiple stakeholders). The next step will be a shared evaluation suite — not just “use RMSE,” but a versioned set of tests that any MMM implementation can run: rolling time-slice CV, stability checks, decomposition plausibility checks, calibration scoring against experiments, and distributional scoring where appropriate.
In other words: an MMM will be able to pass or fail a standardized battery of tests the way software passes unit tests.
Once the community has that, we get something we’ve never had: comparability. Practitioners can argue about assumptions instead of arguing about whose dashboard looks nicer. Vendors can compete on reliability and usability. And researchers can publish results that actually translate back into practice because everyone can reproduce them.
Did I Make a Mistake? Surely the Future Isn’t This Predictable
This article contains 9 fairly specific predictions about the future of MMM. Each of the predictions is plausible and reasonably well-supported (I could add more supporting details, but we’re already at almost 4,000 words).
If I’ve done my job well, you agree with six or seven of the predictions and have reservations about two or three of them. But you’re probably still on the fence about whether the MMM provider community is about to implode as their customer base standardizes on top of open-source MMM frameworks.
That’s okay. The goal was to start a conversation.
The point of view here is that we are in the “suddenly” part of the famous Hemingway quote.

But timing is hard. Bill Gates might very well wind up with the last word. “We always overestimate the change that will occur in the next two years and underestimate the change that will occur in the next ten.”